Writing Quality
4. Error Correction - Page 2
Review Pages
2. Pits and Lands
3. Error Correction - Page 1
4. Error Correction - Page 2
5. Error Correction - Page 3
6. CIRC - Page 1
7. CIRC - Page 2
8. CD Decoding system
9. C1/C2 Errors - Page 1
10. C1/C2 Errors - Page 2
11. EFM - Page 1
12. EFM - Page 2
13. Jitter - Page 1
14. Jitter - Page 2
15. Jitter - Page 3
16. Oscilloscope
17. Jitter at DVD
18. Technologies for Reducing Jitter
19. JVC ENC K2
20. AudioMASTER
21. VariREC
22. TEAC Boost Function
23. Testing Equipement - Page 1
24. Testing Equipement - Page 2
25. Calibration media
26. Tests before recording
27. Tests after recording
28. Atomic Force Microscopy
Writing Quality - Page 3
Error Correction - Page 2
- Errors Detection - Single bit parity
All error-detection and correction techniques are based on the redundancy of data. Practical error detection uses technique in which redundant data is coded so it can be used to efficiently check for errors. The technique of casting out 9s can be used to cast out any number, and forms the basis for a binary error detection method called parity. Given a binary number, a residue bit can be formed by casting out 2s. This extra bit, known as a parity bit, permits error detection, but not correction.
An even parity bit is formed with a simple rule : if the number of 1s in the data word is even, the parity bit is a 0; if the number of 1s in the word is odd, the parity bit is a 1. An 8-bit data word, made into a 9-bit word with an even parity bit, will always have an even number of 1s.
- Cyclic Redundancy Check Code
The cyclic redundancy check code (CRCC) is an error detection method preferred in audio applications. The CRCC is cyclic block code that generates a parity check word. In 1011011010, the six binary 1s are added together to form binary 0110 (6), and this check word is appended to the data word to form the code word for storage.
- Error Correction Codes
With the use of redundant data, it is possible to correct errors that occur during storage or transmission. However, there are many types of codes, different in their designs and functions. The field of error-correction codes is highly mathematical one. In general, two approaches are used: block codes using algebraic methods, and convolution codes using probabilistic methods. In some cases, algorithms use a block code in a convolution structure known as a cross-interleave code. Such codes are used in the CD format.
- Interleaving
Error correction depends on an algorithm's ability to efficiently use redundant
data to reconstruct invalid data. When the error is sustained, as in the case
of a burst
error, both the data and the redundant data are lost, and correction becomes
difficult or impossible. Data is interleaved or dispersed through the data stream
prior to storage or transmission. With interleaving, the largest error that
can occur in any block is limited to the size of the interleaved section. Interleaving
greatly increases burst error correctability of the block codes.
- Cross interleaving
Although the burst is scattered, the random errors add additional errors in a given word, perhaps overloading the correction algorithm. One solution is to generate two correction codes, separated by an interleave and delay. When block codes are arranged in rows and columns two dimensionally, the code is called a product code (in DVD). When two block codes are separated by both interleaving and delay, cross-interleaving results. A cross-interleaved code comprises two (or more) block codes assembled with a convolutional structure.
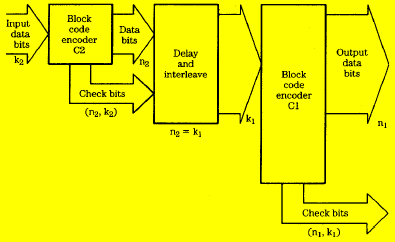
The above picture shows a Cross Interleaving encoder as used in the CD format. Syndromes from the first block are used as error pointers in the second block. In the CD format, k2=24, n2=28, k1=28 and n1=32; the C1 and C2 codes are Reed-Solomon codes.
Review Pages
2. Pits and Lands
3. Error Correction - Page 1
4. Error Correction - Page 2
5. Error Correction - Page 3
6. CIRC - Page 1
7. CIRC - Page 2
8. CD Decoding system
9. C1/C2 Errors - Page 1
10. C1/C2 Errors - Page 2
11. EFM - Page 1
12. EFM - Page 2
13. Jitter - Page 1
14. Jitter - Page 2
15. Jitter - Page 3
16. Oscilloscope
17. Jitter at DVD
18. Technologies for Reducing Jitter
19. JVC ENC K2
20. AudioMASTER
21. VariREC
22. TEAC Boost Function
23. Testing Equipement - Page 1
24. Testing Equipement - Page 2
25. Calibration media
26. Tests before recording
27. Tests after recording
28. Atomic Force Microscopy












