Imec at IEDM 2018
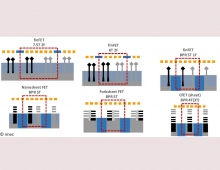
Duigital technology research and innovation hub Imec will present at the 2018 IEEE International Electron Devices Meeting (IEDM) this week a comparison between SRAM- and SST-MRAM-based last-level caches at the 5nm node, a 300mm-wafer platform for MOSFET devices with 2D materials, 3D stacked FinFETs on 300mm wafers, along with gate-all-around (GAA) transistors with vertically stacked nanowires and nanosheets for the N3 technology node.
Stacked Nanowire Gate-All-Around Transistors for N3 and Beyond
Imec will report significant progress in process enabling the introduction of gate-all-around (GAA) transistors with vertically stacked nanowires and nanosheets for the N3 technology node. Results include improved Si GAA devices, better understanding of strain engineering in Ge nanowire pFETs, and a comprehensive understanding of reliability and degradation mechanisms of nanowire FETs.
GAA MOSFETs are promising candidates to extend the gate length and gate pitch scaling beyond what is possible with FinFETs. The use of lateral nanowires or nanosheets has the advantage of a process flow that is not so disruptive compared to FinFET processing. And by stacking the nanowires or nanosheets, the concept allows maximizing the drive current for a given footprint. At last year’s IEDM, imec presented first functional circuits; today the research center presents three studies that include process optimizations and a better understanding of strain engineering and reliability in GAA MOSFETs.
A first study will show how process improvements may significantly reduce the nanowire size and improve the shape controllability without degrading the electrical performance. With these improvements, imec made Si GAA devices with a reduced vertical spacing, a large improvement of Ion/Ioff performance and short channel margin for both nMOS and pMOS devices. The results were demonstrated by an improvement of the gate delay from 24ps down to 10ps in a ring oscillator. A second study compared germanium nanowire pFETs with germanium FinFETs and reveaed the marked advantage of the former, mainly due to a more optimal strain engineering. The original demonstration of this work (IEDM 2017) has received the Paul Rappaport Award (presented at the plenary session at IEDM 2018, Monday Dec 3). Last, an extensive mapping of n-, p- Si and p-Ge nanowire FETs in the entire bias space allowed to characterize the various degradation metrics and reveal multiple active degradation mechanisms.
"Gate-all-around nanowire transistors are promising candidates to replace FinFETs for nodes beyond N5, and this without too much disruption," commented Naoto Horiguchi, distinguished member of the technical staff at imec. "These new results further optimize the processes to realize these transistors and provide us with more understanding, e.g. on optimal strain engineering and degradation mechanisms."
Imec’s research into advanced logic scaling is performed in cooperation with imec’s key CMOS program partners including GlobalFoundries, Huawei, Intel, Micron, Qualcomm, Samsung, SK Hynix, Sony Semiconductor Solutions, TOSHIBA Memory, TSMC and Western Digital.
Stacking FinFETS with 45nm fin pitch using sequential 3D integration
Imec will also present a first demonstration of 3D stacked FinFETs on 300mm wafers using a sequential integration approach with a 45nm fin pitch and 110nm poly pitch technology. The top layer consists of junction-less devices fabricated at a temperature below 525 degrees Celsius in a silicon layer transferred by wafer-to-wafer bonding. The excellent performance of the resulting stack demonstrates how the 3D sequential approach can be deployed to obtain an aggressive device density at advanced nodes.
Sequential-3D integration (S3D) involves the vertical integration of sequentially processed device layers. The technique is slated to enhance device density per chip area, reduce the length of the interconnection lines, and facilitate the co-integration of heterogeneous device technologies. A major technological challenge though is the restricted thermal budget for the top layer processing. At too high temperatures, the bottom tier devices, interconnect layers and wafer bonding dielectric may be impacted. But a limited temperature on the other hand may result in a performance degradation for the top layer and mismatch between the two tiers.
Imec first processed bottom devices using a 300mm silicon bulk FinFET flow featuring a 45-nm fin pitch, a 110 nm gate-pitch and a high-k last replacement metal gate. The top silicon layer is then transferred onto the bottom device layer by wafer-to-wafer bonding with a bonding dielectric stack scaled down to 160nm. On that top silicon layer, FinFET devices are then processed at a temperature below 525 degrees Celsius. The high-precision alignment with the last-processed interconnects in the bottom layer is done using an immersion 193nm lithography stepper. The resulting top tier devices show a performance on par with high-temperature bulk FinFETs for low stand-by power applications (LSTP). This demonstrates the suitability of this technology to enable applications combining analog/LSTP top tier devices on High Performance (HP) bottom tier devices.

"With this process, we managed to solve many of the outstanding challenges of sequential 3D processing. An example is the extremely precise alignment of the first-processed top layer with the last-processed bottom layer, which we managed using 193nm immersion lithography," commented Nadine Collaert, program director at imec. "These results demonstrate the suitability of the 3D sequential approach for an aggressive device density enhancement at future technology nodes."
Direct growth of 2D materials on 300mm wafers
Imec will also present a 300mm-wafer platform for MOSFET devices with 2D materials. 2D materials could provide the path towards extreme device-dimension scaling as they are atomically precise and suffer little from short channel effects. Other possible applications of 2D materials could come from using them as switches in the BEOL, which puts an upper limit on the allowed temperature budget in the integration flow.
The imec platform integrates as transistor channel WS2, a 2D material which holds promise for higher ON current compared to most other 2D materials and good chemical stability. Imec reports here for the first time the MOCVD growth of WS2 on 300mm wafers, a key process step for device fabrication. The MOCVD synthesis approach results in thickness control with monolayer precision over the full 300mm wafer and potentially highest mobility matrial. The benefits of the MOCVD growth come at the price of a high temperature while growing the material.
To build a device integration flow which could be compatible with BEOL requirements, the transfer of the channel material from a growth substrate to a device wafer is crucial. Imec is the first to demonstrate a full 300mm monolayer 2D material transfer, which is very challenging on its own because of the low adhesion of 2D materials to the device wafer and to the exteme thinness of the material transferred: 0.7nm! The transfer process was developed together with SUSS MicroTec and Brewer Science using temporary bonding and debonding technologies. WS2 wafers are temporarily bonded to glass carrier wafers using a specially formulated material (Brewer Science). Next, the WS2 monolayer is mechanically debonded from the growth wafer and bonded again in vacuum to the device wafer. The carrier wafer is removed using laser debonding. This debonding technique is a key enabler for the controlled transfer of 2D materials.

Iuliana Radu, Beyond CMOS Program Director at imec, explains, "Building the 300mm platform for MOSFET device study with 2D materials and developing the process step ecosystem speeds-up the technological adoption of these materials. Several challenges are still to be resolved and are the subject of ongoing research and development." Major challenges include scaling the equivalent oxide thickness (EOT) of gate dielectric for 2D materials, and reducing channel defectivity to boost mobility.
Feasibility of Introducing SST-MRAM as a Last-Level Cache at the 5nm Technology Node
Imec will present a power-performance-area comparison between SRAM- and SST-MRAM-based last-level caches at the 5nm node. The analysis, based on design-technology co-optimization and silicon verified models, reveals that STT-MRAM meets the performance requirements for last-level caches in the high-performance computing domain. Moreover, for larger memory densities, significant energy gains are found for SST-MRAM compared to SRAM.
The increased complexity of CMOS transistor processing has led to the limited scaling of high-density SRAM cells at advanced technology nodes. STT-MRAM has emerged as a promising candidate for replacing the SRAM-based last level cache memories for systems with reduced area and energy. The core element of an STT-MRAM device is a magnetic tunnel junction in which a thin dielectric layer is sandwiched between a magnetic fixed layer and a magnetic free layer. Writing of the memory cell is performed by switching the magnetization for the free magnetic layer, by means of a current that is injected into the magnetic tunnel junction.
Imec analyzed the feasibility of introducing STT-MRAM at the 5nm technology node for the high-performance computing domain. In a first step, a design-technology co-optimization (DTCO) was performed to define the requirements and specifications for SST-MRAM cells at the 5nm node. Imec concluded that a high-performance 2*Perpendicular-to-Plane (CPP) STT-MRAM bit cell (with MRAM pitch being twice the contacted gate pitch (CPP) of 45nm) is the preferred solution for last-level caches at 5nm, using 193 immersion single patterning lithography, resulting in lower technology cost. DTCO also reveals the requirement for the current density that is needed to enable a high switching speed of the magnetic tunnel junction. For a target current density of 3.8 to 5.4mA/cm2, a resistance area product of 3.1 to 4.7Ωµm2 is required.
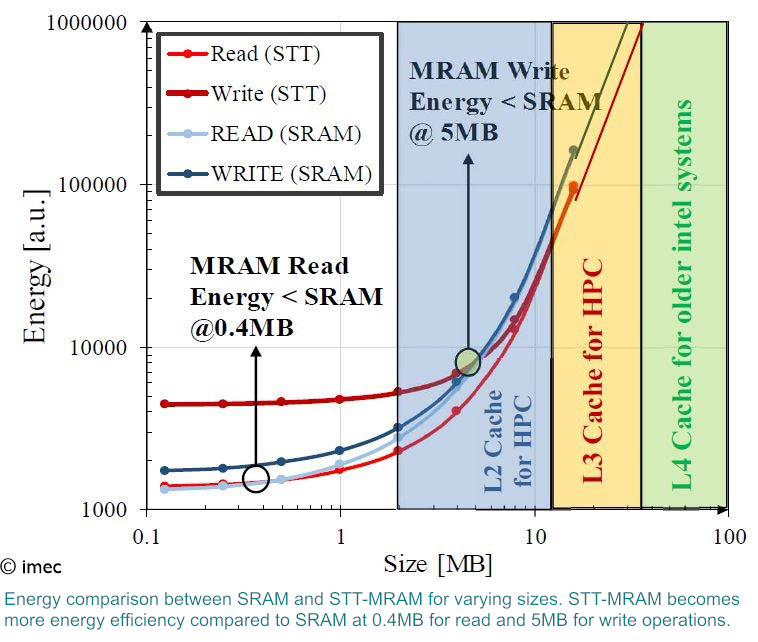
In a second step, a high-performance STT-MRAM cell was fabricated on 300mm Si wafers and the characteristics of the magnetic tunnel junction were measured experimentally. These Si verified data were then used in a model that allowed to compare the SRAM and STT-MRAM last-level cache designs for the high-performance computing domain at the 5nm node. In these designs, the STT-MRAM cell occupies an area of 43.3% of the SRAM macro.
Gouri Sankar Kar, Program director at imec: “For the first time, DTCO and Si verified models allowed us to conclude that the STT-MRAM energy becomes more efficient as compared to SRAM for high-density memory cells (i.e., beyond 0.4MB and 5MB density for read and write operations, respectively). The comparison also reveals that the latency of the STT-MRAM is sufficient to meet the requirements of the last-level caches in the high-performance computing domain, which operate around 100MHz clock frequency.”