
Arm today provided more details about the Project Trillium machine learning IPs and specifically the "machine learning processor" or MLP, at a press event in Austin, Texas.
Anounced earlier this year, Arm's architecture comes a bit later than other approaches, with the first silicon to come in smartphones next year.
The first core targets 4.6 tera operations/second (TOPS) and 3 TOPS/W at 7 nm for high-end handsets. Arm plans simpler variants using less memory for mid-range phones, digital TVs, and other devices.
In terms of scalability the MLP is meant to come with configurable compute engine setups from 1 CE up to 16 CEs and a scalable SRAM buffer up to 1MB.
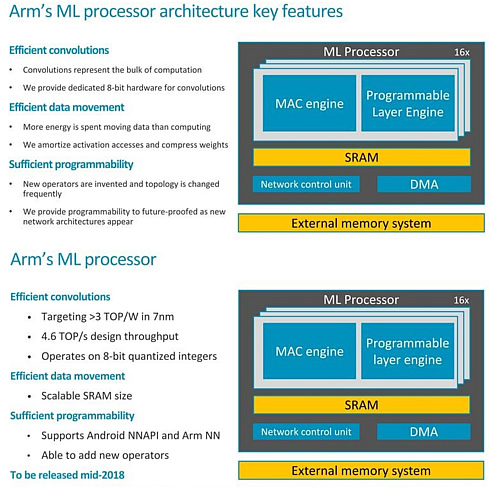
From a high level perspective the MLP has a set of multiple-accumulate (MAC) engines (up to 16) for the raw computational power,
a programmable engine, and a configurable SRAM block, typically about a megabyte.
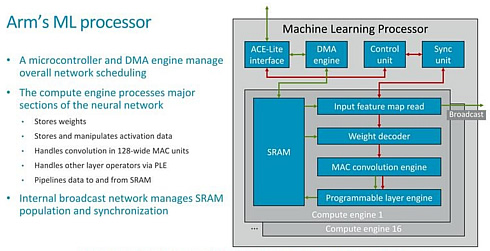
The compute engines each contained fixed function blocks which operate on the various layers of the neural network model, such as input feature map read blocks which pass onto control information to a weight decoder.
The actual convolution engine has is a 128-wide MAC unit operating on 8-bit integer data storing the quantised weights of the NN model.
The core supports pruning and clustering of weights to maximize performance. It uses tiling to keep working data sets in SRAM and reduce the need to access external DRAM.
The programmable layer engine (PLE) on each slice of the core offers "just enough programmability to perform [neural-net] manipulations" but doesn't include the legacy baggage of instruction fetch-and-decode blocks, said Robert Elliot, a technical director in Arm's machine-learning group.

The PLE includes a vector engine that acts as a lookup table to handle pooling and activation tasks.
Arm plans to release the enw core in mid-June.
One customer is already using Arm's open-source libraries for neural networks to support jobs across a third-party accelerator and a Mali GPU. The code supports both Android and embedded Linux.